








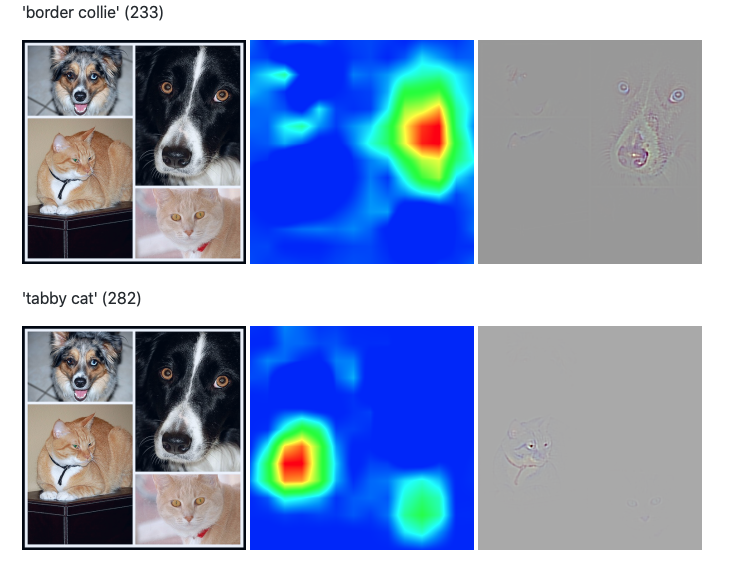
Grad-CAM
Grad-CAMは、CNNのクラス分類根拠を可視化する手法です。
CNN(DNN)はブラックボックス→Interpretabality(説明可能性)が必要です。
画像のクラスを判断するときにどこに着目しているのかを可視化させます。
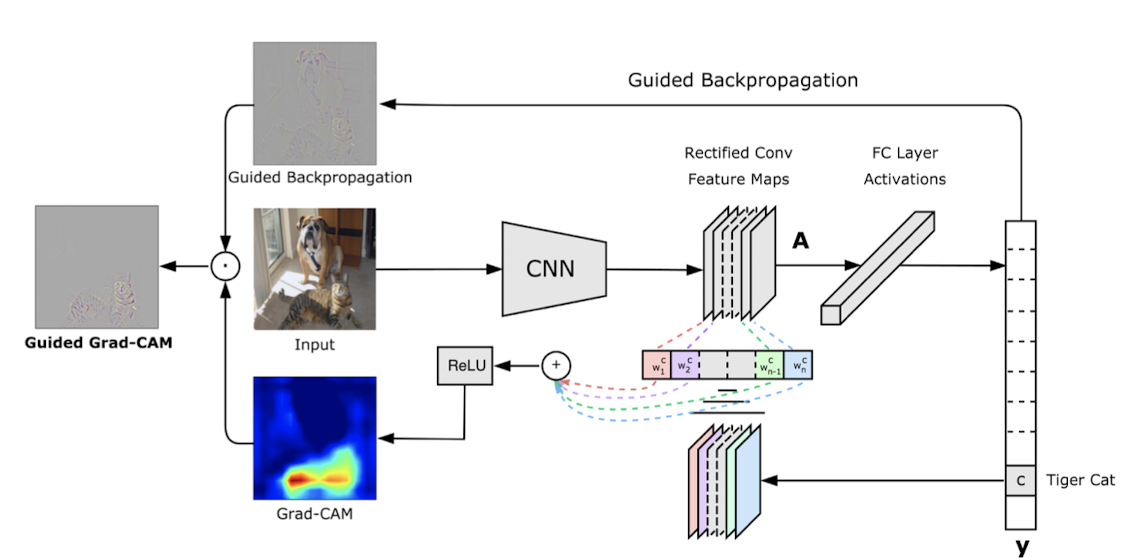
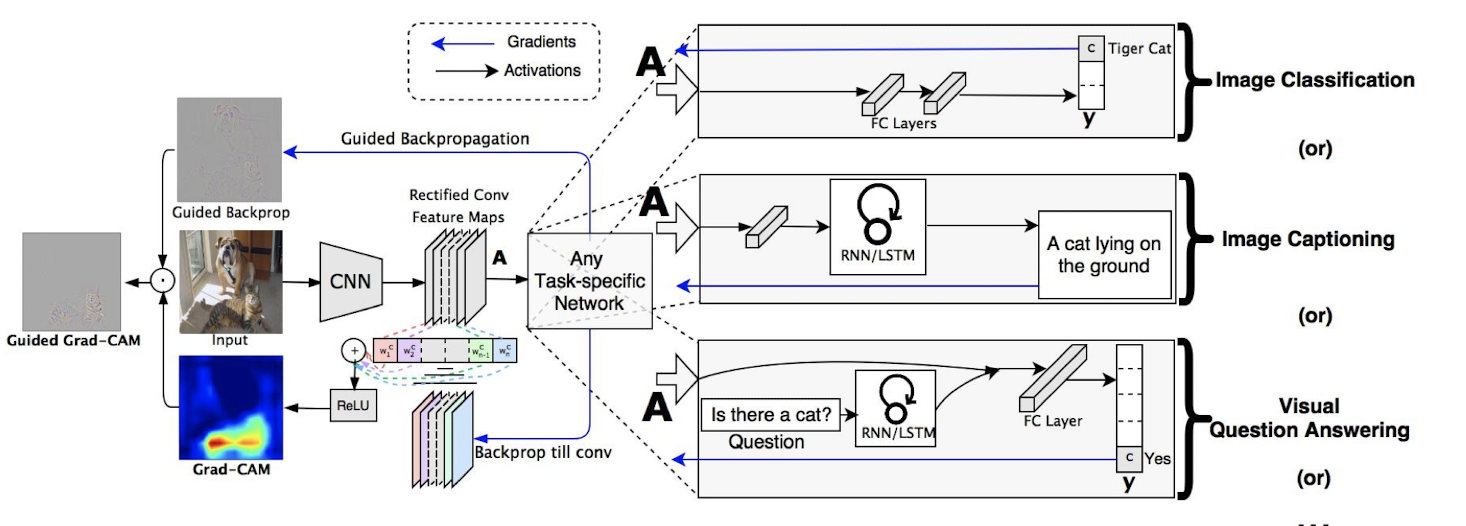
Grad-CAMの論文では、Grad-CAMに加え、既存手法のGuided BackpropagationとGrad-CAMを組み合わせたGuided Grad-CAMも提案されています。
また、これらの手法に加え、従来の画像分類タスクに限らず、画像キャプショニングやVQAへの応用についても実験されています。
Paper
Arxivでは、4回ほどアップデートされています。
一番初めは、”Grad-CAM: Why did you say that? Visual Explanations from Deep Networks via Gradient-based Localization”というタイトルでした。
最新のversion4は、”Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization. “です。
一応このversion1とversion4のリンクを貼っておきますが、arxivのversionを見れば大丈夫です。
Version 1
Version 4
(2019). Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization. Version4
アーキテクチャ
画像分類を使ったGrad-CAMがV1では紹介されていた。
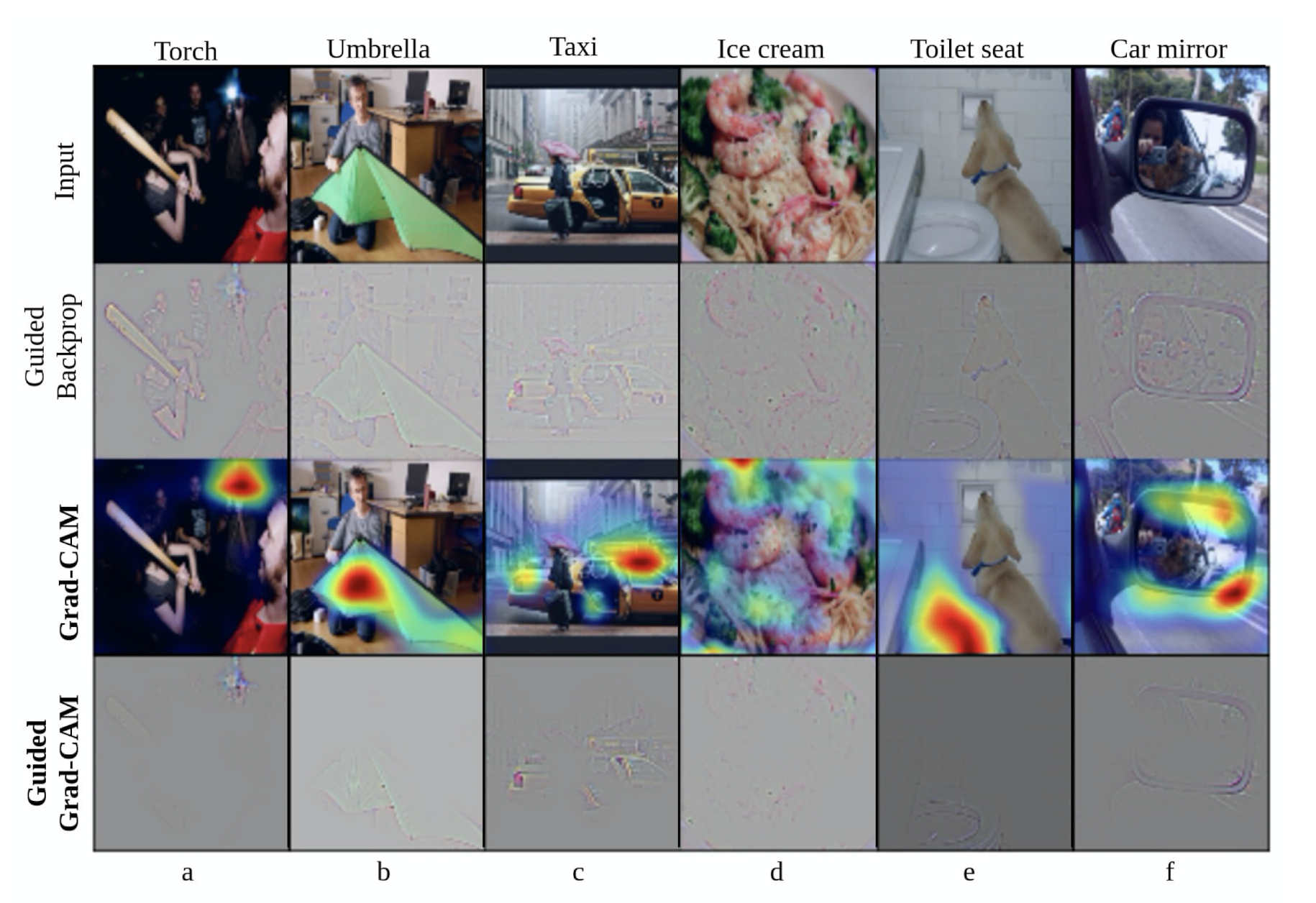
V4では、画像分類だけでなく、他のタスク(画像キャプションやVQAなど)への応用が追加されている。
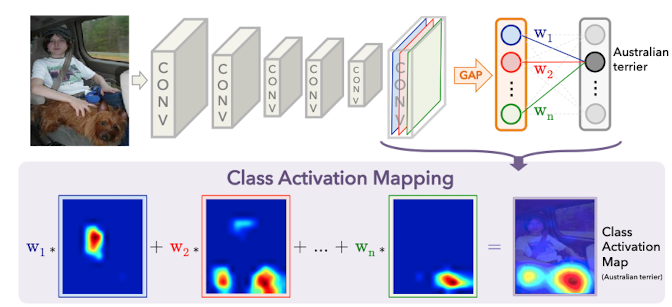
元になったCAM(http://Learning Deep Features for Discriminative Localization)のアーキテクチャは下図です。
重み\(\omega^c_k\)をGradientに変えたものがGrad-CAMです。
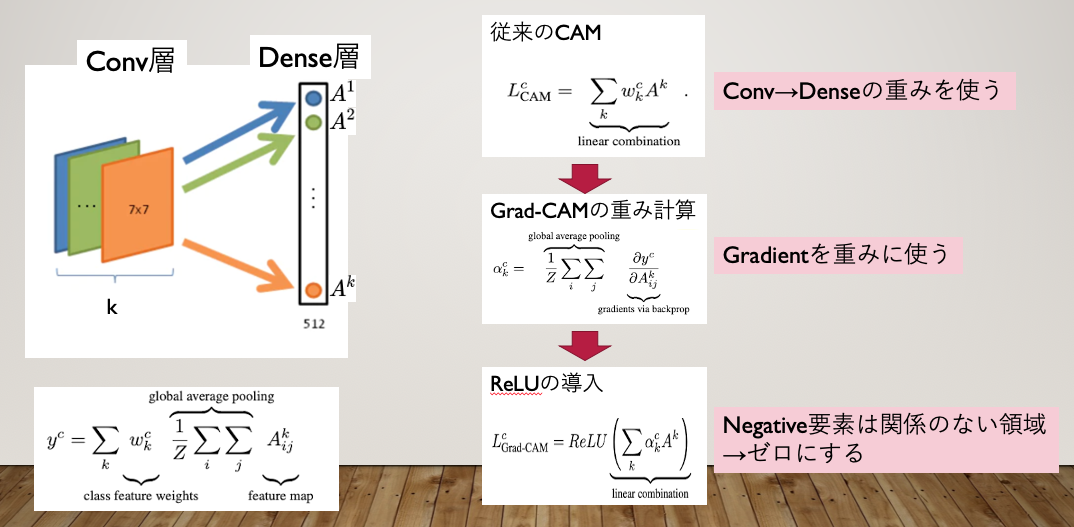
Gradient\(\alpha^c_k\)は次のように定義されています。
$$
\alpha^c_k = \frac{1}{Z} \sum_i \sum_j \frac{\partial Y^c}{\partial A^k_{ij}}
$$
重み\(\omega^c_k\)は次のように表せて、式変形します。
$$
\omega^c_k = Z \frac{\partial Y^c}{\partial A^k_{ij}}
\\
\frac{\partial Y^c}{\partial A^k_{ij}} = \frac{1}{Z}\omega^c_k
$$
これをGradientの式に代入することによって、次のように表せます。
$$
\begin{align}
\alpha^c_k &= \frac{1}{Z} \frac{1}{Z} \sum_i \sum_j \omega^c_k \\
&= \frac{1}{Z} \omega^c_k
\end{align}
$$
先行手法のCAMの\(\omega^c_k\)に比例定数\(\frac{1}{Z}\)で、normalizeした結果(+ReLU)がGrad-CAMになっています。
このため、Grad-CAMは、厳密にCAMの派生系と言えます。
Grad-CAMでは、CAMを\(\frac{1}{Z}\)でNormalizeした後に、ReLUでNegativeを0にします。
ClassにPositiveな関係が強いと思われるものだけを抽出することになります。
$$
L_{\text {Grad-CAM}}^{c}=\operatorname{ReLU}\left(\sum_{k} \alpha_{k}^{c} A^{k}\right)
$$
これを逆に利用して、ClassにNegativeな関係があると思われるものだけを抽出することもできます。
$$
L_{\text {Grad-CAM}}^{c}=\operatorname{ReLU}\left(- \sum_{k} \alpha_{k}^{c} A^{k}\right)
$$
直感的に、
Positiveを採用したものは、”どこに重要か”
Negativeを採用したものは、”どこが重要でないか”
を表しているのかな??
【メモ】Global Average Pooling
GAPとは、Global Average Poolingで、各チャネルに対して、カーネルを用いずに、全画素の平均をとることです。

Guided Grad-CAM
論文中には、既存手法のGuided Backpropagationと組み合わせた”Guided Grad-CAM”が提案されています。
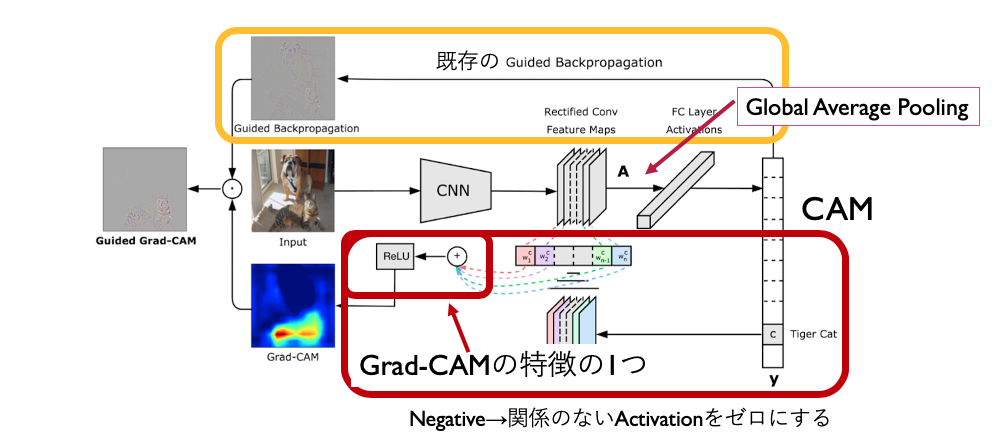
Guided Backpropagationが提案された(紹介されている)論文は、こちらです。
Jost Tobias Springenberg, Alexey Dosovitskiy, Thomas Brox, Martin Riedmiller(2014). Striving for Simplicity: The All Convolutional Net.
実装
まだ理解出来てないです。
参考にしているリンクを置きます。

