








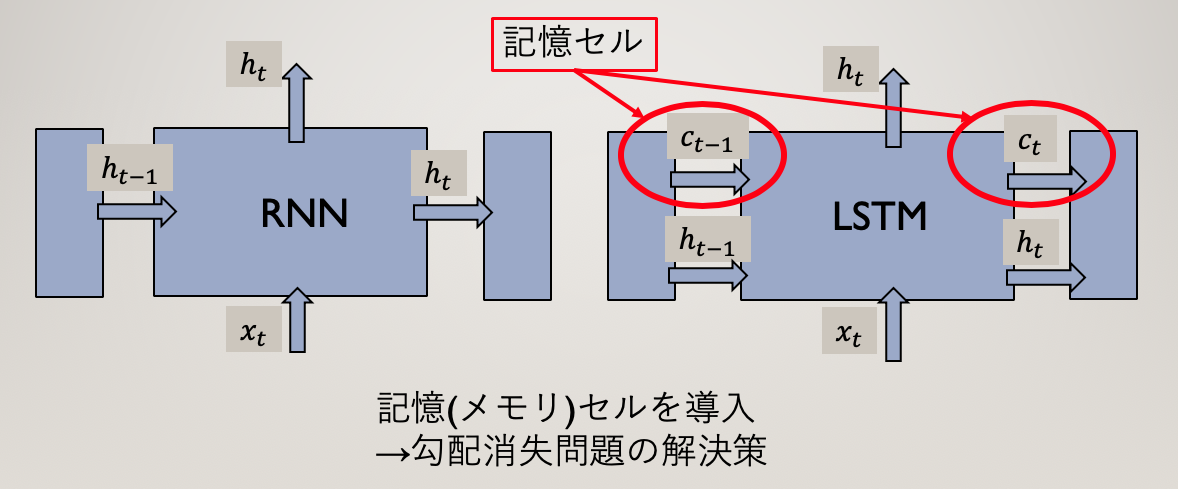
LSTM
単純なRNN(Elmanとも呼ぶ)では、勾配消失や勾配爆発の発生が問題となっています。
勾配消失には、勾配クリッピングが有効です。
勾配消失には、ゲート付きRNN(LSTMやGRU)が有効です。
LSTMには、”input”・”forget”・”output”の3つのゲートがあります。
LSTMの構造
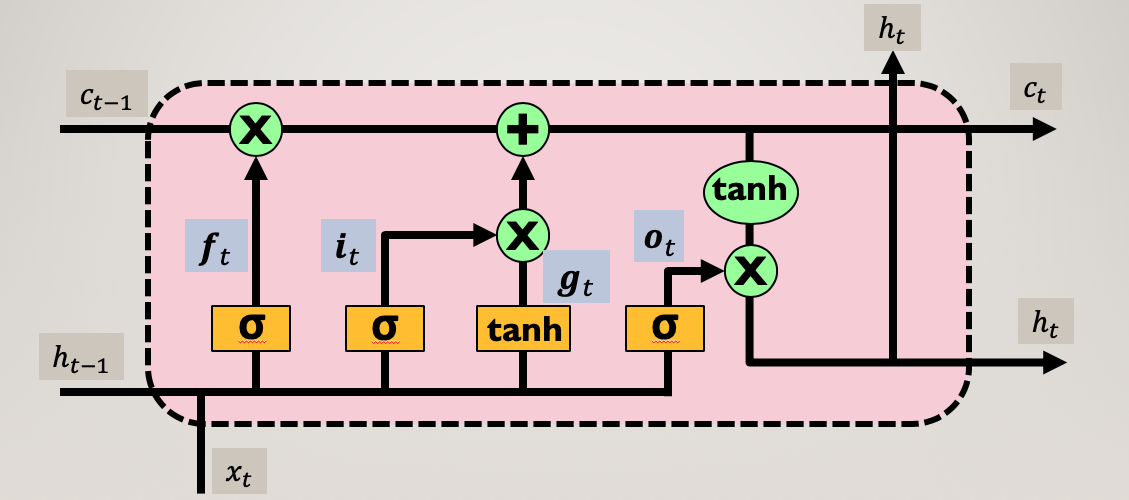
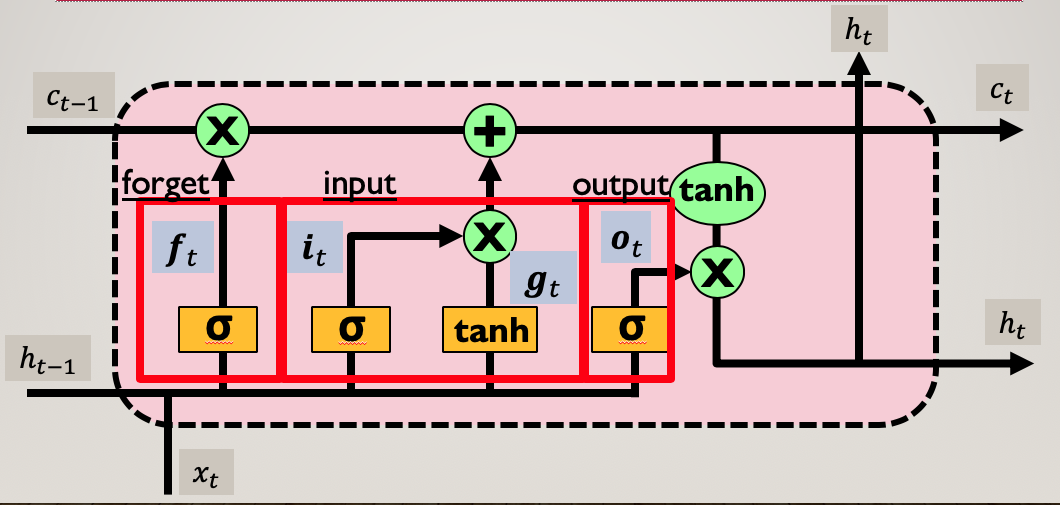
ゲート
forget
勾配消失を防ぐために、誤差を内部にとどまらせるための記憶セルを用意しています。
必要な情報を必要なタイミングで保持させ、必要でない情報を必要なタイミングで忘却させるためのforgetゲートです。
$$
\mathbf{f}=\sigma\left(\mathbf{x}_{t} \mathbf{W}_{\mathbf{x}}^{(\mathbf{f})}+\mathbf{h}_{t-1} \mathbf{W}_{\mathbf{h}}^{(\mathbf{f})}+\mathbf{b}^{(\mathbf{f})}\right)
$$
input
入力重み衝突を防ぐため
$$
\begin{array}{l}i=\sigma\left(x_{t} W_{x}^{(i)}+h_{t-1} W_{h}^{(i)}+b^{(i)}\right) \\ g=\tanh \left(\mathbf{x}_{t} \mathbf{W}_{\mathbf{x}}^{(\mathbf{g})}+\mathbf{h}_{t-1} \mathbf{W}_{\mathbf{h}}^{(\mathbf{g})}+\mathbf{b}^{(\mathbf{g})}\right)\end{array}
$$
output
出力重み衝突を防ぐため
$$
\mathbf{o}=\sigma\left(\mathbf{x}_{t} \mathbf{W}_{\mathbf{x}}^{(\mathbf{o})}+\mathbf{h}_{t-1} \mathbf{W}_{\mathbf{h}}^{(\mathbf{o})}+\mathbf{b}^{(\mathbf{o})}\right)
$$
LSTMの出力
記憶せるの出力
$$
c_{t}=f \odot c_{t-1}+g \odot i
$$
隠れユニットの出力
$$
\mathbf{h}_{t}=\mathbf{o_t} \odot \tanh \left(\mathbf{c}_{t}\right)
$$
参考
- Understanding LSTM Networks|colah’s blog
- LSTMネットワークの概要
- LONG SHORT-TERM MEMORY
- Example of Many-to-One LSTM|discuss.pytorch


