PytorchでCNN
ディープラーニングで最近人気が出てきているPytorchで、CNNを学習していきます。
プログラムはブロックごとに分けて、紹介します。
今回使用するデータセットは、scikit-learnのdigitsデータセットです。
このdigitsは、手書き文字のMNISTと似ていますが、画像サイズが(8,8)とかなり小さいです。
ちなみに、MNISTの画像サイズは、(28, 28)です。
また、データ数は、1797です。
プログラムの解説と流れ
importするライブラリ
# データを訓練用と検証用に分割 import numpy as np from sklearn.datasets import load_digits from sklearn.model_selection import train_test_split import torch from torch import nn, optim from torch.utils.data import Dataset, DataLoader,TensorDataset import time import matplotlib.pyplot as plt %matplotlib inline
digitsデータセットの整形
digits.dataが入力で、digits.targetが正解ラベルになります。
まず、正規化します。
次に、digits.dataを、2次元(画像)として扱うために、reshapeします。
PytorchのConv層は、(batch_size, channel, W, H)となっていることに注意してください。
Kerasの場合は、(batch_size, W, H, channel)となっています。
データを学習用とテスト用に分けるために、train_test_splitを使って、データを分割します。
digits = load_digits() # 全体の30%は検証用 X = digits.data y = digits.target #正規化0~1 X = X/255 print(X.shape) #shape=(1797, 64) X = X.reshape(-1, 1, 8, 8) print(X.shape) #shape=(1797, 1, 8, 8) train_X, test_X, train_y, test_y = train_test_split(X, y, test_size=0.3, random_state=1)
tensorに変換
Pytorchのtensorにデータを変換します。
#テンソル型に変換する X_train = torch.tensor(train_X, dtype=torch.float32) y_train = torch.tensor(train_y, dtype=torch.int64) X_test = torch.tensor(test_X, dtype=torch.float32) y_test = torch.tensor(test_y, dtype=torch.int64)
DatasetとDataLoader
#データセット train = torch.utils.data.TensorDataset(X_train,y_train) test = torch.utils.data.TensorDataset(X_test,y_test) #データローダー train_loader = torch.utils.data.DataLoader(train, batch_size = 32, shuffle = False) test_loader = torch.utils.data.DataLoader(test, batch_size = 32, shuffle = False)
ネットワークの定義
#ネットワークの定義
class net(nn.Module):
def __init__(self):
super(net,self).__init__()
#畳み込み層
self.conv_layers = nn.Sequential(
nn.Conv2d(in_channels = 1, out_channels = 16, kernel_size = 2, stride=1, padding=0),
nn.Conv2d(in_channels = 16, out_channels = 32, kernel_size = 2, stride=1, padding=0),
)
#全結合層
self.dence = nn.Sequential(
nn.Linear(32 * 6 *6, 128),
nn.Dropout(p=0.2),
nn.Linear(128, 64),
nn.Dropout(p=0.2),
nn.Linear(64, 10),
)
#順伝播
def forward(self,x):
out = self.conv_layers(x)
#Flatten
out = out.view(out.size(0), -1)
#全結合層
out = self.dence(out)
return out
#畳み込み層の出力サイズのチェック
def check_cnn_size(self, size_check):
out = self.conv_layers(size_check)
return out
デバイス選択と畳み込み層の出力サイズの確認
#デバイスの状態を確定 device = 'cuda' if torch.cuda.is_available() else 'cpu' #net()をデバイスに渡す net = net().to(device) #畳み込み層の出力サイズ=全結合層のinput_sizeの確認 size_check = torch.FloatTensor(10, 1, 8, 8) size_check = size_check.to(device) print(net.check_cnn_size(size_check).size())
損失関数と最適化の選択
損失関数を選択します。
最適化を選択します。
#損失関数 criterion = nn.CrossEntropyLoss() #最適化 optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9, weight_decay=5e-4)
学習
num_epochs = 100
train_loss_list = []
train_acc_list = []
val_loss_list = []
val_acc_list = []
import time
start = time.time()
for epoch in range(num_epochs):
train_loss = 0
train_acc = 0
val_loss = 0
val_acc = 0
#train
net.train()
for i, (images, labels) in enumerate(train_loader):
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = net.forward(images)
loss = criterion(outputs, labels)
train_loss += loss.item()
train_acc += (outputs.max(1)[1] == labels).sum().item()
loss.backward()
optimizer.step()
avg_train_loss = train_loss / len(train_loader.dataset)
avg_train_acc = train_acc / len(train_loader.dataset)
#val
net.eval()
with torch.no_grad():
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = net.forward(images)
loss = criterion(outputs, labels)
val_loss += loss.item()
val_acc += (outputs.max(1)[1] == labels).sum().item()
avg_val_loss = val_loss / len(test_loader.dataset)
avg_val_acc = val_acc / len(test_loader.dataset)
print ('Epoch [{}/{}], Loss: {loss:.4f}, val_loss: {val_loss:.4f}, val_acc: {val_acc:.4f}'
.format(epoch+1, num_epochs, i+1, loss=avg_train_loss, val_loss=avg_val_loss, val_acc=avg_val_acc))
train_loss_list.append(avg_train_loss)
train_acc_list.append(avg_train_acc)
val_loss_list.append(avg_val_loss)
val_acc_list.append(avg_val_acc)
end = time.time() - start
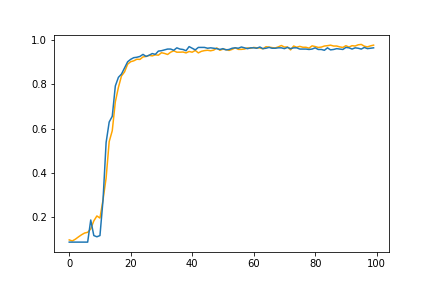
精度のグラフ化
plt.plot(train_acc_list, color='orange') plt.plot(val_acc_list) plt.legend;