
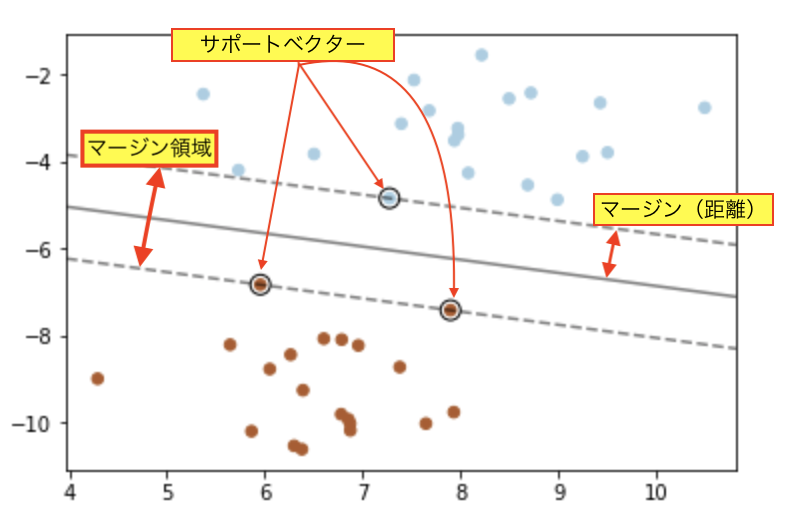









グリッドサーチ
グリッドサーチは、パラメータをチューニングしてモデルの汎化性能を向上させる方法。
sklearnでグリッドサーチ
パラメータの辞書を作ります。
GridSearchCVに、
- モデル
- パラメータ辞書
- 交差検証の分割数
渡します。
後の、学習と推論(予測)の作業はいつも通りの、fitとpredictで実行します。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import accuracy_score
iris = load_iris()
train_X, val_X, train_y, val_y = train_test_split(iris.data, iris.target, test_size=0.2, random_state=0)
params_grid = {'C': [0.001, 0.01, 0.1, 1, 10, 100],
'gamma':[0.001, 0.01, 0.1, 1, 10, 100]}
grid_search = GridSearchCV(SVC(), params_grid, cv=5)
grid_search = grid_search.fit(train_X, train_y)
params = grid_search.best_params_
print("best_paramerters is ",params)
print("best_score is ", grid_search.best_score_)
pred = grid_search.predict(val_X)
print("accuracy is ", accuracy_score(pred, val_y))
上のgrid_searchのparamsに最適なパラメータが格納されているので、シンプルにSVCを再実装して、予測を行うこともできます。
svc = SVC(**params) svc.fit(train_X, train_y) pred = svc.predict(val_X) print(accuracy_score(pred, val_y))
グリッドサーチ×1つ抜き交差検証法
言うまでもなく、1つ抜き交差検証法はデータ数が大きくなると膨大な時間がかかる。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import accuracy_score
from sklearn.model_selection import KFold, LeaveOneOut
iris = load_iris()
train_X, val_X, train_y, val_y = train_test_split(iris.data, iris.target, test_size=0.2, random_state=0)
params_grid = {'C': [0.001, 0.01, 0.1, 1, 10, 100],
'gamma':[0.001, 0.01, 0.1, 1, 10, 100]}
loo = LeaveOneOut()
grid_search = GridSearchCV(SVC(), params_grid, cv=loo)
grid_search = grid_search.fit(train_X, train_y)
params = grid_search.best_params_
print("best_paramerters is ",params)
print("best_score is ", grid_search.best_score_)
pred = grid_search.predict(val_X)
print("accuracy is ", accuracy_score(pred, val_y))
参考
https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.GridSearchCV.html