










pytorchのインストール
下のサイトにインストール方法が載っています。
一応、pytorchの公式サイトです。
https://pytorch.org/
私の環境では、Anacondaを使って、pytorchを入れました。
コマンドを書いときます。
conda install pytorch torchvision -c pytorch
PyTorchでGPUを使う
Windows10でGPU環境を整える
PythonでGPUを使うCUDA10
Pytorch
torch.nn
ニューラルネットワークを構築するための様々なデータ構造やレイヤーが定義されている。
torch.optim
確率的勾配降下法を中心とした最適化アルゴリズムが実装されている
torch.utils.data
SGDの繰り返し計算を回す際のミニバッチを作るためのユーティリティ関数が含まれている。
Tensor
Tensorとは、多次元配列を扱うためのデータ構造
自動微分
Tensorにはrequires_gradという属性があり、これをTrueにすることで自動微分を行なうフラグが有効になる。
ニューラルネットワークを扱う場合、パラメータやデータはすべてこのフラグがゆうこうになっている。
requires_gradが有効なTensorに対して様々な演算を積み重ねていくことで計算グラフが構築され、backwardメソッドを呼ぶと、その情報から自動微分される。
DatasetとDataLoader
ミニバッチ学習データのシャッフル、さらには並列処理を簡単に行える
TensorDatasetはDatasetを継承したクラスで特徴量XとラベルYをまとめるコンテナであり、このTensorDatasetをDataLoaderにわたすことで、forループでデータの一部のみを簡単に受け取れるようになっている
TensorDatasetにはTensorのみ渡すことができ、Variableは渡せない
Pytorchでニューラルネットワークを実装
学習データは、sklearn.datasets.load_digitsを使用します。
サンプルコード
import torch
from torch import nn
from torch import optim
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from torch.utils.data import TensorDataset, DataLoader
digits = load_digits()
X = digits.data
y = digits.target
#学習用データとテストデータに分ける
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.3)
X_train = torch.tensor(X_train, dtype=torch.float32)
X_test = torch.tensor(X_test, dtype=torch.float32)
y_train = torch.tensor(y_train, dtype=torch.int64)
y_test = torch.tensor(y_test, dtype=torch.int64)
#ミニバッチ学習
ds = TensorDataset(X_train, y_train)
loader = DataLoader(ds, batch_size=32, shuffle=True)
#ネットワーク構築
net = nn.Sequential(
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, 16),
nn.ReLU(),
nn.Linear(16, 10)
)
#損失関数
loss_fn = nn.CrossEntropyLoss()
#最適化
optimizer = optim.Adam(net.parameters())
train_losses = []
test_losses = []
train_accuracy = []
test_accuracy = []
#学習
for epoch in range(100):
running_loss = 0.0
for i, (XX, yy) in enumerate(loader):
optimizer.zero_grad()
y_pred = net(XX)
loss = loss_fn(y_pred, yy)
loss.backward()
optimizer.step()
running_loss += loss.item()
train_losses.append(running_loss/i)
y_pred = net(X_test)
test_loss = loss_fn(y_pred, y_test)
test_losses.append(test_loss.item())
print("epoch{0}:train={1};test={2}".format(epoch+1,running_loss/i,test_loss.item()))
_, y_pred = torch.max(net(X_train), 1)
train_accuracy.append((y_pred == y_train).sum().item() / len(y_train))
_, y_pred = torch.max(net(X_test), 1)
test_accuracy.append((y_pred == y_test).sum().item() / len(y_test))
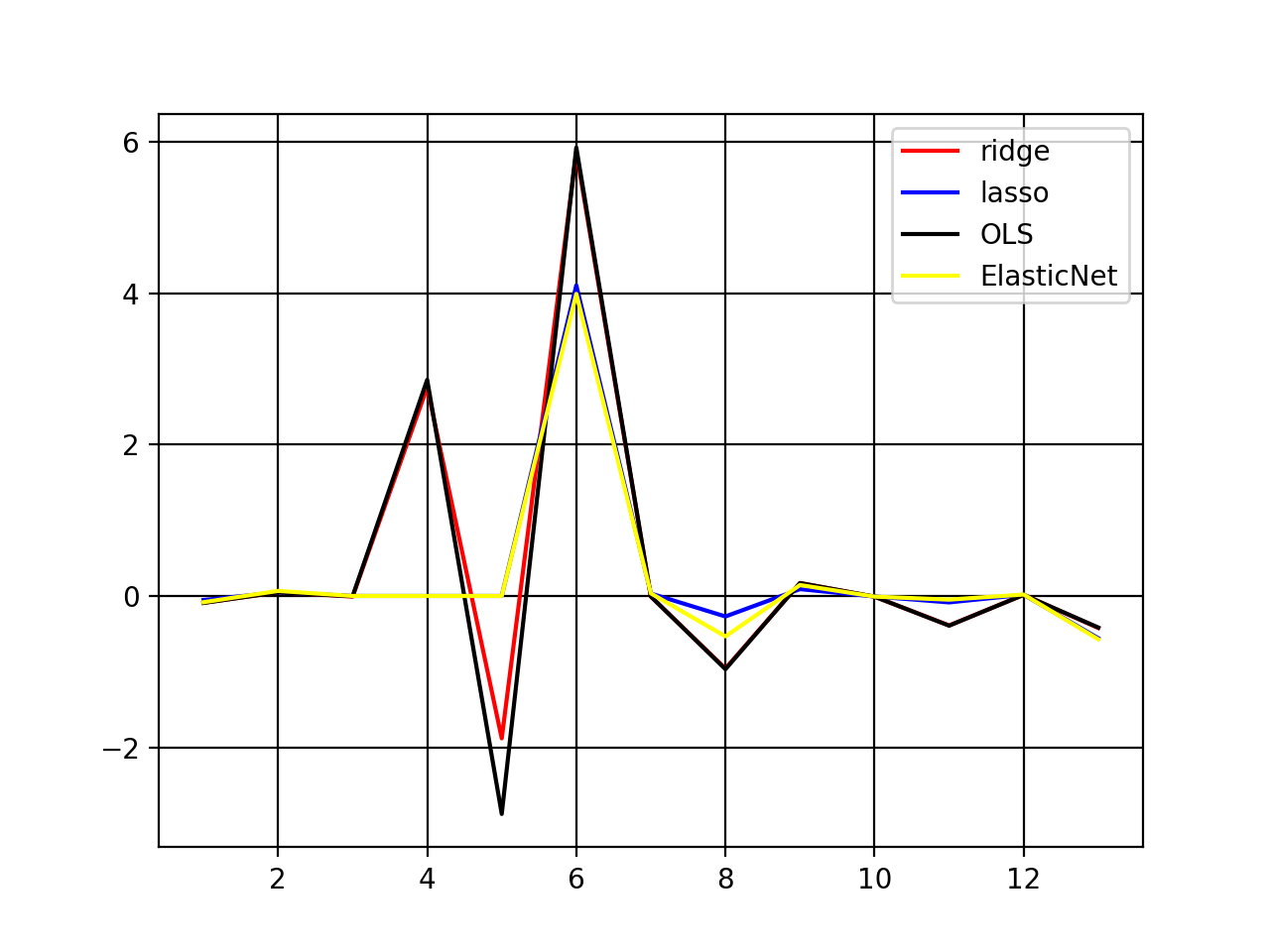
lossをグラフ化
matplotで一応lossのグラフ化をしようと思います。
%matplotlib inline
import matplotlib.pyplot as plt
plt.plot(train_losses, label="train")
plt.plot(test_losses, label="test", color="orange")
plt.legend()
plt.savefig('train_test_loss.png')
plt.show()
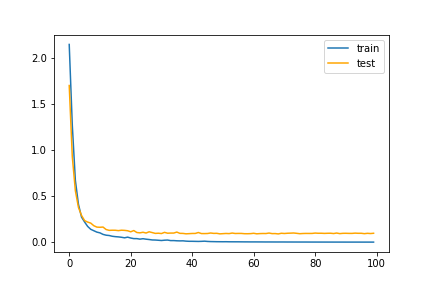
Accuracyの計算
plt.plot(train_accuracy, label="train", color="blue")
plt.plot(test_accuracy, label="test", color="orange")
plt.legend()
plt.savefig('train_test_accuracy.png')
plt.show()
DatasetとDataLoader
#ミニバッチ学習
ds = TensorDataset(X_train, y_train)
loader = DataLoader(ds, batch_size=32, shuffle=True)
#学習
for epoch in range(100):
running_loss = 0.0
for i, (XX, yy) in enumerate(loader):
optimizer.zero_grad()
y_pred = net(XX)
loss = loss_fn(y_pred, yy)
loss.backward()
optimizer.step()
running_loss += loss.item()
train_losses.append(running_loss/i)
y_pred = net(X_test)
test_loss = loss_fn(y_pred, y_test)
test_losses.append(test_loss.item())
print("epoch{0}:train={1};test={2}".format(epoch+1,running_loss/i,test_loss.item()))
ネットワークのモジュール化
Pytorchで独自ネットワークを作るには、nn.Moduleを継承したクラスを定義します。
nn.Moduleは、nn.Linearなどのすべての層の基底クラスになっている。
カスタム層を作る際には、forwardメソッドを実装すれば、自動微分まで可能になる。
class MLP(nn.Module):
def __init__(self, in_features, out_features, bias=True, p=0.5):
super().__init__()
self.linear = nn.Linear(in_features, out_features, bias)
self.relu = nn.ReLU()
self.drop = nn.Dropout(p)
def __call__(self, x):
t = self.linear(x)
t = self.relu(t)
t = self.drop(t)
return t
使い方
mlp = MLP(64, 10) mlp(X_train)