







k-最近傍法
今回のテーマは、k-最近傍法です。
機械学習の分類問題で、一番簡単なアルゴリズムです。
*ここでは、近傍の距離の求め方、アルゴリズム等には触れません。今後触れていけたらな思います。
予測は、訓練データの中から、テストデータに1番近い点つまり、最近傍点を見つける。
kとは、近傍点の数を示す。
最も多く現れたクラスをその点に与える。多数派のクラスを採用する。
KNeighbors分類器は、近傍点の数は3,5程度の大きさで十分である。
距離の計算は、ユークリッド距離を用いるのが一般的
k最近傍法は、アルゴリズムは理解しやすい
処理速度が遅く、多数の特徴量を扱うことができないため、実際には殆ど使われていない
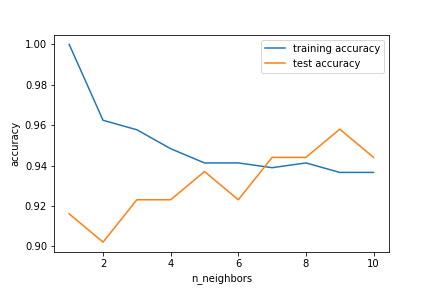
k-最近傍法の精度グラフ
sklearn.neighbors.KNeighborsRegressor
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.metrics import accuracy_score
cancer = load_breast_cancer()
train_X, val_X, train_y, val_y = \
train_test_split(cancer.data, cancer.target, random_state=0)
training_accuracy = []
test_accuracy = []
neighbors_settings = range(1,11)
for n_neighbors in neighbors_settings:
clf = KNeighborsClassifier(n_neighbors=n_neighbors)
clf.fit(train_X, train_y)
training_accuracy.append(accuracy_score(clf.predict(train_X), train_y))
test_accuracy.append(accuracy_score(clf.predict(val_X), val_y))
plt.plot(neighbors_settings, training_accuracy, label="training accuracy")
plt.plot(neighbors_settings, test_accuracy, label="test accuracy")
plt.ylabel("accuracy")
plt.xlabel("n_neighbors")
plt.legend()
結果
おまけ
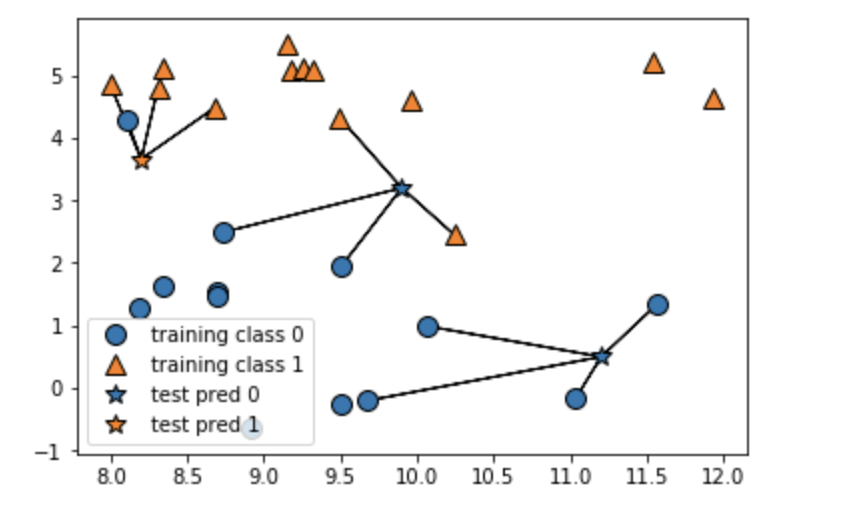
コード
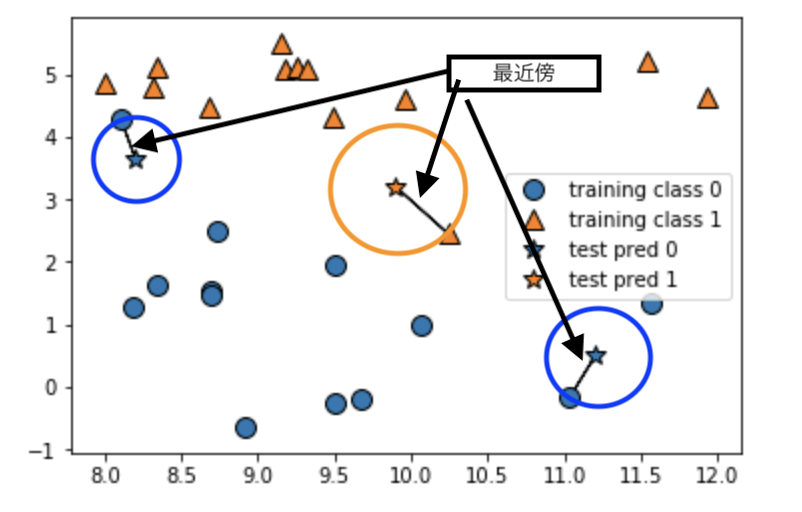
import numpy as np import mglearn import pandas as pd import matplotlib.pyplot as plt from sklearn.datasets import load_boston boston = load_boston() X, y = mglearn.datasets.load_extended_boston() mglearn.plots.plot_knn_classification(n_neighbors=1)
結果
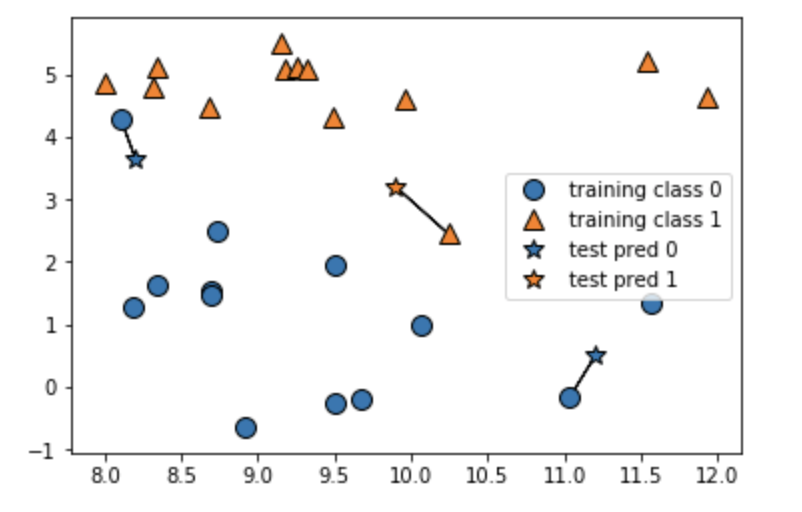
2~4最近傍
2最近傍
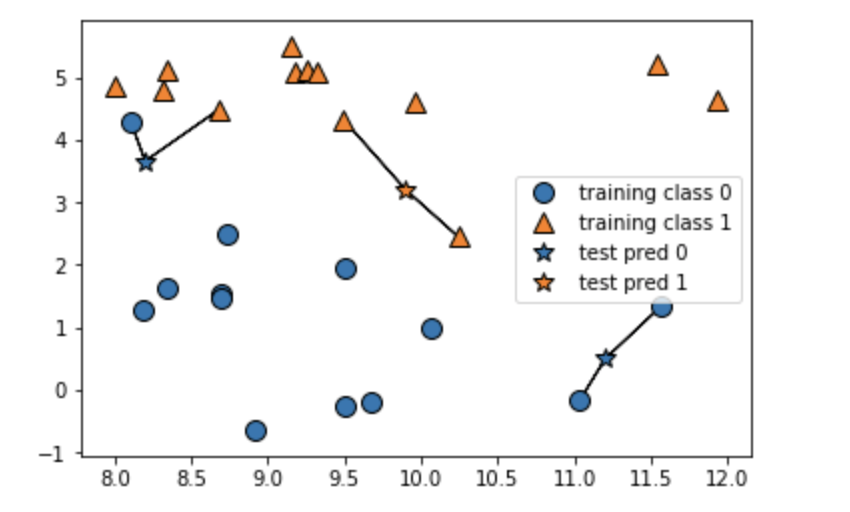
3最近傍
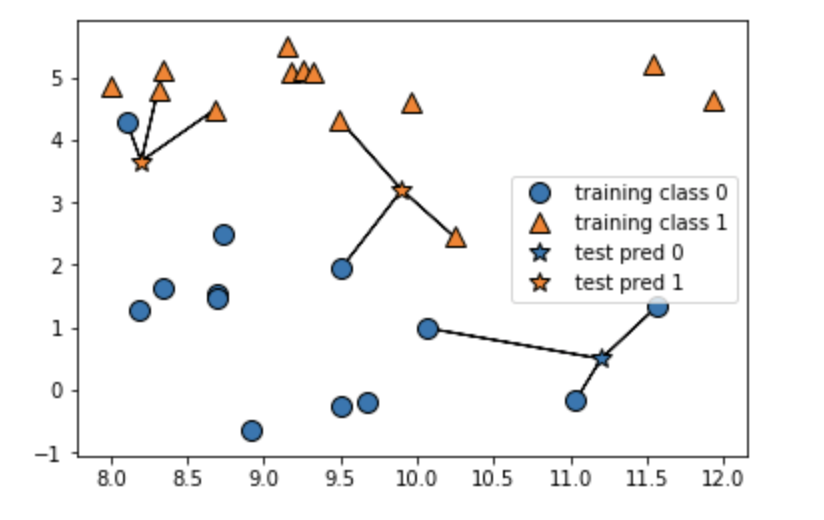
4最近傍
感想
k-最近傍法の理論(考え方)は、分かりやすいと思います。
ただ、ここでは数理的な理論には触れていない
理解しやすさと引き換えに、多数の特徴量が扱えないなどの制限があり、利用されていないようです。