

サポートベクターマシン(SVM)
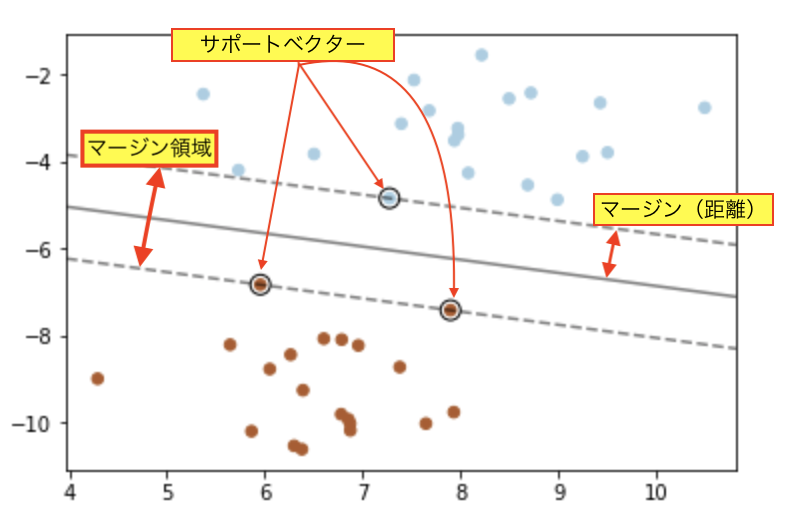
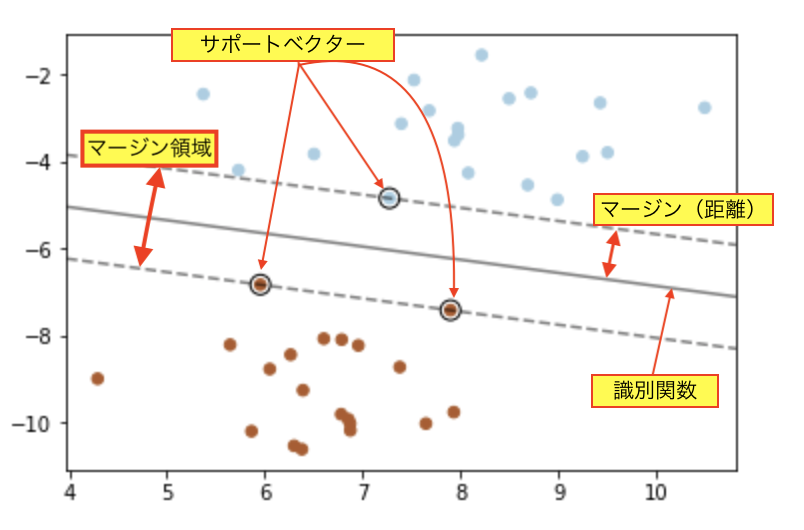
データの分布を分ける溝(境界線)を求める。
多層パーセプトロンのようなデータの分類と似ている。
サポートベクターマシンでは、データの距離(マージン)を最大にして、その真ん中を通る識別関数を解析的に求める。
マージン領域が最大になるデータ点をサポートベクターと呼ぶ。
カーネルトリックと呼ばれる方法で非線型の識別関数を決めることができる。
sklearn SVC
from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split X = load_iris().data y = load_iris().target X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1) from sklearn.svm import SVC svc = SVC(kernel='linear') svc.fit(X_train, y_train) accuracy_score(svc.predict(X_test),y_test)
参考

1.4. Support Vector Machines
...
scikit-learn
SVM: Maximum margin separating hyperplane
...
scikit-learn