







最適なモデル選んだら、評価する必要あり
機械学習では、様々なモデル(アルゴリズム)が存在する。
scikit-learnでも、多くのモデルが用意されている。
前回の最適なモデル選びall_estimatorsで、最適なモデル(アルゴリズム)の選ぶ方法を紹介しました。
all_estimators()を使うことで、正解率が高い=最適なモデルを選ぶことができる。
モデルが決まったら、そのモデルを評価しましょう。
精度が安定しないモデルは、正答率が高くてもあまりいいモデルとは言えません。
この安定性を見る方法として、交差検証法を使います。
交差検証法とは?
交差検証法(Cross-Validation)は、データを学習データと検証データに分け、その誤差を評価基準とする、パラメータの最適化方法です。
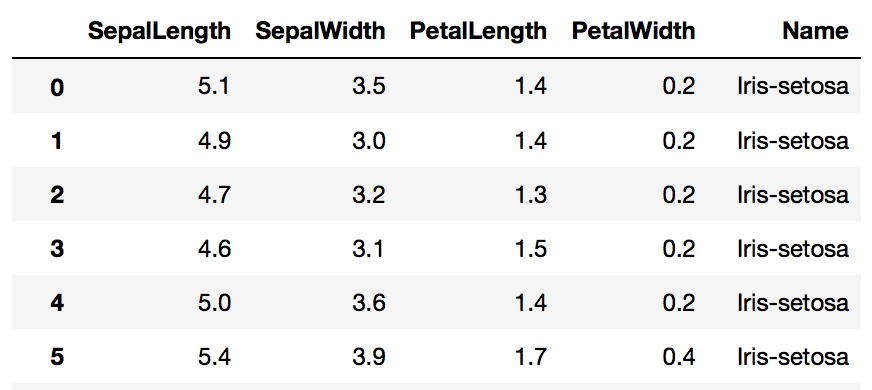
irisデータを学習する
SepalLength、SepalWidth、PetalLength、PetalWidthの4つの変数から、Nameを予測する。
データの形式
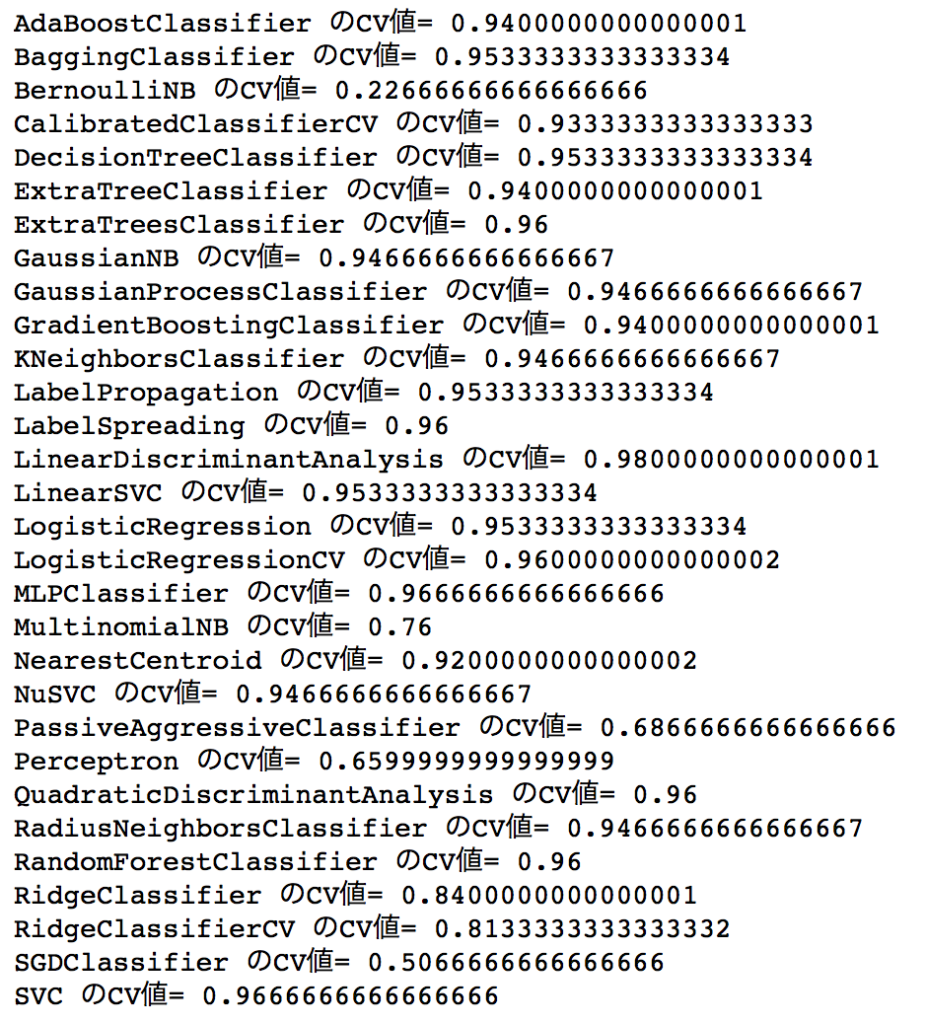
結果

K-分割交差検証
K=5と指定したので、正解率は5つ出力されます。
ソースコード
import numpy as np
import pandas as pd
from sklearn.metrics import accuracy_score
from sklearn.model_selection import KFold, cross_val_score, LeaveOneOut, ShuffleSplit, GroupKFold
from sklearn.utils.testing import all_estimators
from sklearn.datasets import load_iris
import warnings
warnings.filterwarnings('ignore')
X = load_iris().data
y = load_iris().target
allAlgorithms = all_estimators(type_filter="classifier")
kfold_cv = KFold(n_splits=5, shuffle=False)
for (name, algorithm) in allAlgorithms:
clf = algorithm()
if hasattr(clf, "score"):
scores = cross_val_score(clf, X, y, cv=kfold_cv)
#print(name,"の正解率=", scores)
print(name, "CV値=",scores.mean())
CV値
交差検証法で出された正解率は、K個あるので平均を取ります。
この値をCV値と呼びます。
for (name, algorithm) in allAlgorithms:
clf = algorithm()
if hasattr(clf, "score"):
scores = cross_val_score(clf, X, y, cv=kfold_cv)
print(name,"のCV値=", scores.mean())
1つ抜き交差検証法
loo = LeaveOneOut()
for (name, algorithm) in allAlgorithms:
clf = algorithm()
if hasattr(clf, "score"):
scores = cross_val_score(clf, X, y, cv=loo)
#print(name,"の正解率=", scores)
print(name, "CV値=",scores.mean())
シャッフル交差検証法
shuffle_split = ShuffleSplit(test_size=0.5, n_splits=10)
for (name, algorithm) in allAlgorithms:
clf = algorithm()
if hasattr(clf, "score"):
scores = cross_val_score(clf, X, y, cv=shuffle_split)
#print(name,"の正解率=", scores)
print(name, "CV値=",scores.mean())
