







最適なモデル選び
0.18では動きます。
機械学習では、様々なモデル(アルゴリズム)が存在する。
scikit-learnでも、多くのモデルが用意されている。
all_estimators()を使うことで、正解率が高い=最適なモデルを選ぶことができる。
all_estimatorsでは、分類問題・回帰問題・クラスタリング問題を選択できる。
それぞれ、‘classifier’, ‘regressor’, ‘cluster’
データの形が合わないとエラーが出るので、全てに対応していないと全てのモデルをテストできないことに注意
sklearn.utils.testing.all_estimators
classifier:分類問題を扱う
SepalLength、SepalWidth、PetalLength、PetalWidthの4つの変数から、Nameを予測する。
データの形式
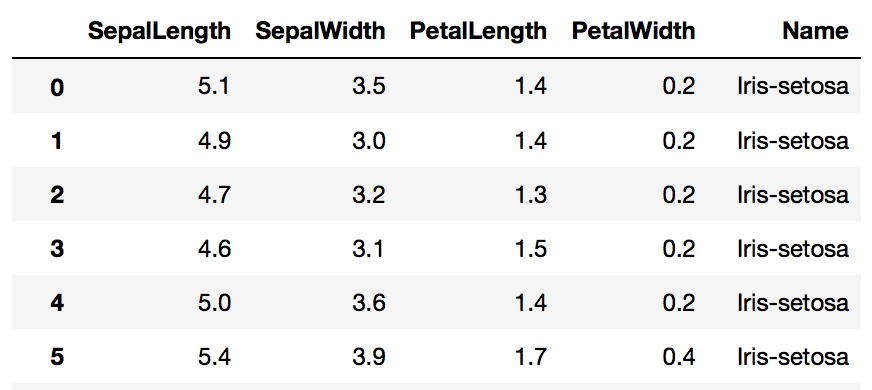
結果

以上の結果から、正解率の高いモデルを選べば良い。
ソースコード
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.utils.testing import all_estimators
from sklearn.datasets import load_iris
import warnings
warnings.filterwarnings('ignore')
iris = load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=False)
#最適なモデルを選ぶall_estimators()
allAlgorithms = all_estimators(type_filter="classifier")
for (name, algorithm) in allAlgorithms:
clf = algorithm()
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(name,"の正解率=", accuracy_score(y_test, y_pred))
regressor:回帰問題
from sklearn.utils.testing import all_estimators
from sklearn.datasets import load_diabetes
from sklearn.metrics import mean_squared_error
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
diabetes = load_diabetes()
# 説明変数データを取得
data_X = pd.DataFrame(diabetes.data, columns=diabetes.feature_names)
#被説明変数データを取得
data_y = pd.DataFrame(diabetes.target, columns=['target'])
from sklearn.model_selection import train_test_split
train_X, test_X, train_y, test_y = train_test_split(data_X, data_y, test_size=0.4, random_state=0)
allAlgorithms = all_estimators(type_filter="regressor")
for (name, algorithm) in allAlgorithms:
clf = algorithm()
clf.fit(train_X, train_y)
pred_y = clf.predict(test_X)
print(name,"の正解率=", np.sqrt(mean_squared_error(test_y, pred_y)))