










BoWとは
BoWは、Bag-of-Wordsの略です。
BoWは、テキストを数値の特徴ベクトルに変換する方法です。
テキストデータに対して、テキスト中の特定の単語の出現回数を特徴量にする。
PythonでBoW-CountVectorizer-
日本語の場合、文は、単語もしくは形態素にスペース等ではっきり分かれていない。
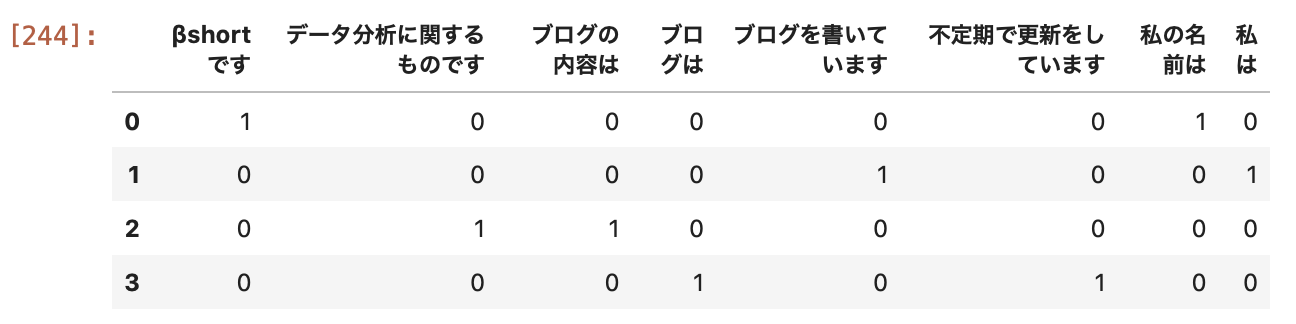
そのため、日本語のテキストをそのままBoW処理すると以下のような結果になってしまう。
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
import MeCab
text_list = ["私の名前は、βshortです。",
"私は、ブログを書いています。",
"ブログの内容は、データ分析に関するものです。",
"ブログは、不定期で更新をしています。"]
#==== bow ====
bow = CountVectorizer()
count = bow.fit_transform(text_list)
vec = count.toarray()
name = bow.get_feature_names()
#==== pandasで出力を確かめる=====
pd.DataFrame(vec, columns=name)
これを防ぐために、日本語テキストでは、まず初めに”分かち書き”をする。
分かち書き+CountVectorizer
この分かち書きについては、下のページで紹介する。
Pythonで日本語の分かち書き|βshort Lab
分かち書き後のBoWの結果は下のようになる。
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
import MeCab
def clear(text):
text = re.sub(r'、', '', text)
text = re.sub(r'。', '', text)
text = re.sub(r'\n', '', text)
return text
text_list = ["私の名前は、βshortです。",
"私は、ブログを書いています。",
"ブログの内容は、データ分析に関するものです。",
"ブログは、不定期で更新をしています。"]
for i in range(len(text_list)):
tagger = MeCab.Tagger("-Owakati")
text_list[i] = tagger.parse (text_list[i])
text_list[i] = clear(text_list[i])
bow = CountVectorizer()
count = bow.fit_transform(text_list)
vec = count.toarray()
name = bow.get_feature_names()
pd.DataFrame(vec, columns=name)
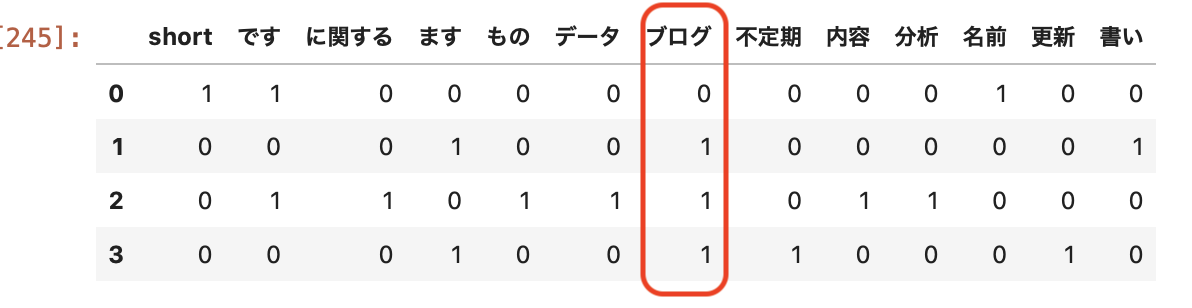
これらの文章は、”ブログの話をしているものだろう”ということが予測できる?
BoWは、文章中の単語の数を特徴量として扱う。
従って、文章の特性に限らず、頻繁に使われる単語は意味がない。
例えば、”です”、”ます”など
頻度による制限-min_dfとmax_df
全ての文書に登場する単語は意味がない(特徴がない)と考えられるので、max_dfで制限します。
全く出現しないような単語は意味がない(特徴がない)と考えられるので、min_dfで制限します。
max_dfとmin_dfは、0~1.0の数値で指定します。
n-gram
#====1gram==== ngram_range(1,1) #もしくは、指定しない #====2gram==== ngram_range(2,2) #====3gram==== ngram_range(3,3) #====1と2gram==== ngram_range(1,2)
ngramは、大体1~3gram程度にします。
多くても4gramぐらいな印象です。

