









Pandasでよく使うもの
import pandas as pd
csvファイルの読み込み
X = pd.read_csv("ファイル名")
csvファイルの出力
output.to_csv('output.csv')
#index=Falseで、index名なし
#columns=Falseで、columns名なし
DataFrameを作成
辞書型で作成
col_array1 = np.array([1,2,3,4,5])
col_array2 = col_array1 + 1
data_dic = {'a':col_array1,
'b' : col_array2}
dataset2 = pd.DataFrame(data_dic)
dataset
値、行、列を取得する
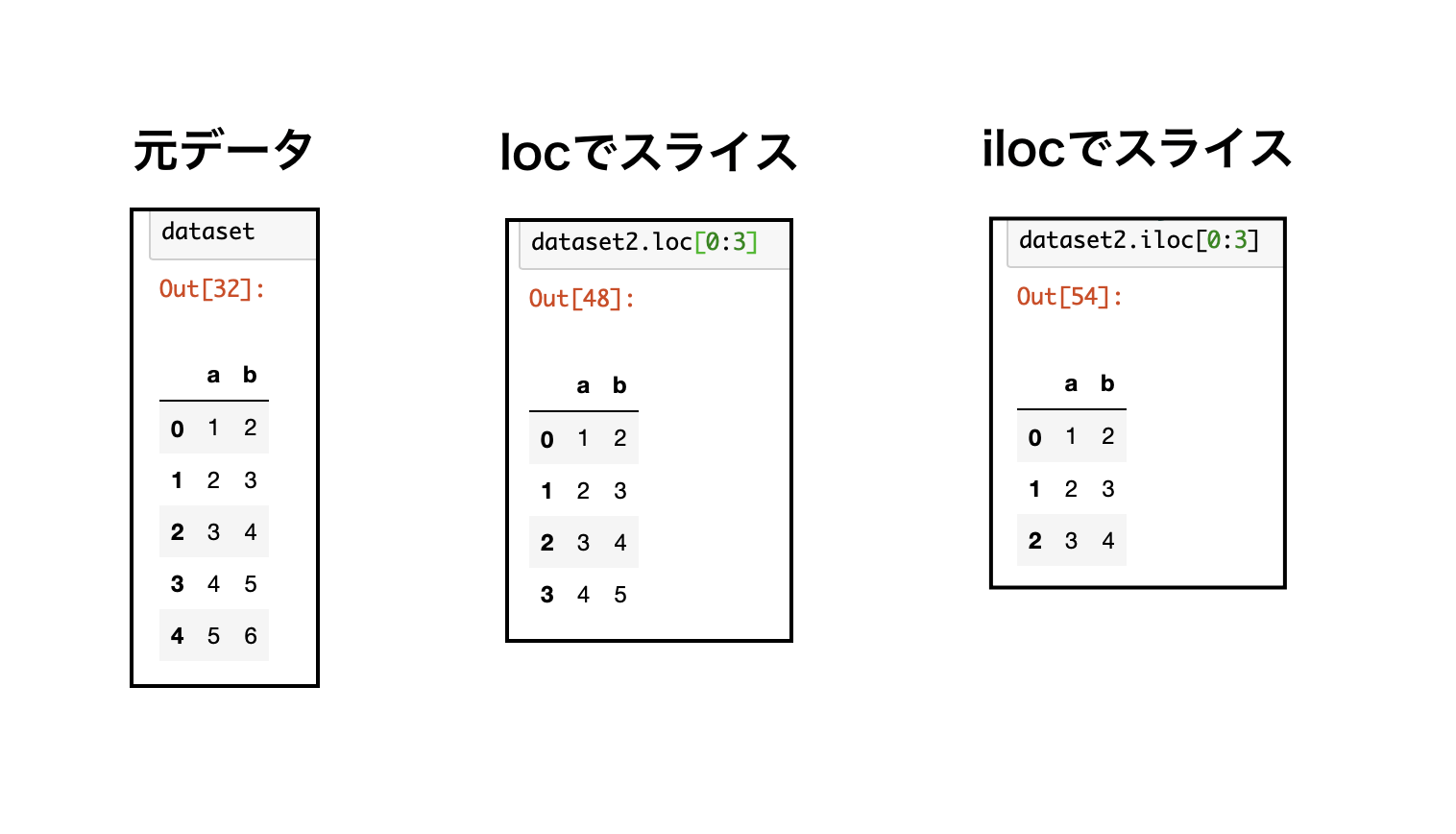
locとiloc
locは、明示的なインデックスを使う。
ilocは、Python由来のインデックスを使う。
列(columns)を抽出したい
#columnsは、列の名前 data.columns #または data['columns']
列の削除
.drop()を使用
pd.drop(['columns'], axis=1)
numpy配列に変換する
.valuesを使用
pd.values
列の名前を取得する
pd.columns
演算メソッド
+:.add()
-:sub(), subtract()
*:mul(), multiply()
/:truediv(), div(), divide()
//:floordiv()
%:mod()
**:pow()
データの基本統計量をみる
train.describe()
| stats | id |
|---|---|
| count | データの個数 |
| mean | 平均 |
| std | 標準偏差 |
| min | 最小値 |
| 25% | 四分の1の値 |
| 50% | 四分の2の値 |
| 75% | 四分の3の値 |
| max | 最大値 |