




Ridge回帰
Ridge回帰は、過剰適合を防ぐための正則化で、モデルを制約する。
Ridge回帰で使用される正則化は、L2正則化である。
リッジ回帰は、ぴったり0に縮小することが出来ないことに注意が必要です。
合わせて、以下のページも見てください。
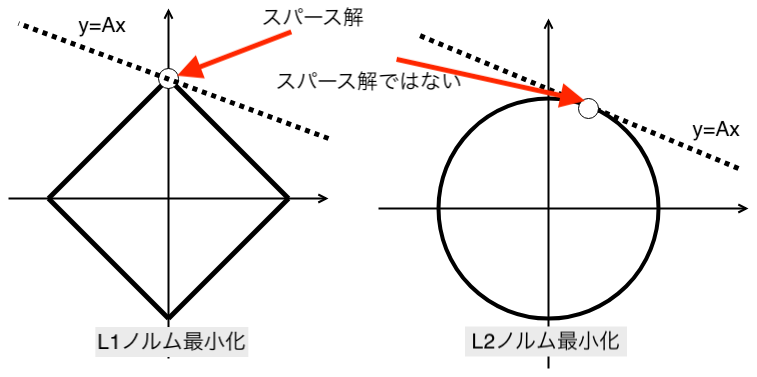
スパースモデリング-入門メモ-
...
betashort-lab.com
2018.06.28
プログラム
係数を表示するプログラムです。
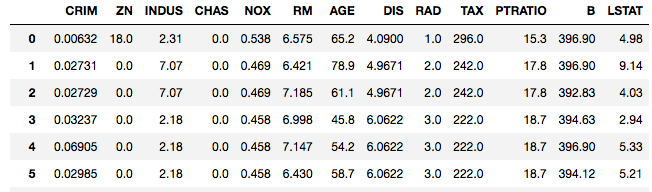
データには、ボストンデータを使います。
Xの変数は、13個の重回帰式になります。
ridge回帰を実行していきましょう。
ソースコード
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from sklearn.linear_model import Ridge
from sklearn.datasets import load_boston
# サンプルデータを用意
dataset = load_boston()
# 説明変数データを取得
data_x = pd.DataFrame(dataset.data, columns=dataset.feature_names)
#被説明変数データを取得
data_y = pd.DataFrame(dataset.target, columns=['target'])
#データのサイズ
print("説明変数行列のサイズ:{}".format(data_x.shape[1]))
print("被説明変数のサイズ:{}".format(data_y.shape))
print("説明変数の変数の個数:{}".format(data_x.shape[1]))
#変数の数
coef_n = data_x.shape[1]
#小数以下n桁
decimal_p = 2
#ridge回帰の偏係数
ridge = Ridge().fit(data_x, data_y)
print(ridge.coef_.round(decimal_p))
結果
[[-1.000e-01 5.000e-02 -1.000e-02 2.550e+00 -1.079e+01 3.850e+00
-1.000e-02 -1.370e+00 2.900e-01 -1.000e-02 -8.800e-01 1.000e-02
-5.300e-01]]
ridgeは、0に向けて近づくだけなので、0になることがないです。
lasso
lassoについては、以下のページを見てください。

Pythonで機械学習-LASSO-
...
betashort-lab.com
2018.06.28
